Google's Conversational Attributes: A Field Report from One of the First Real Uploads
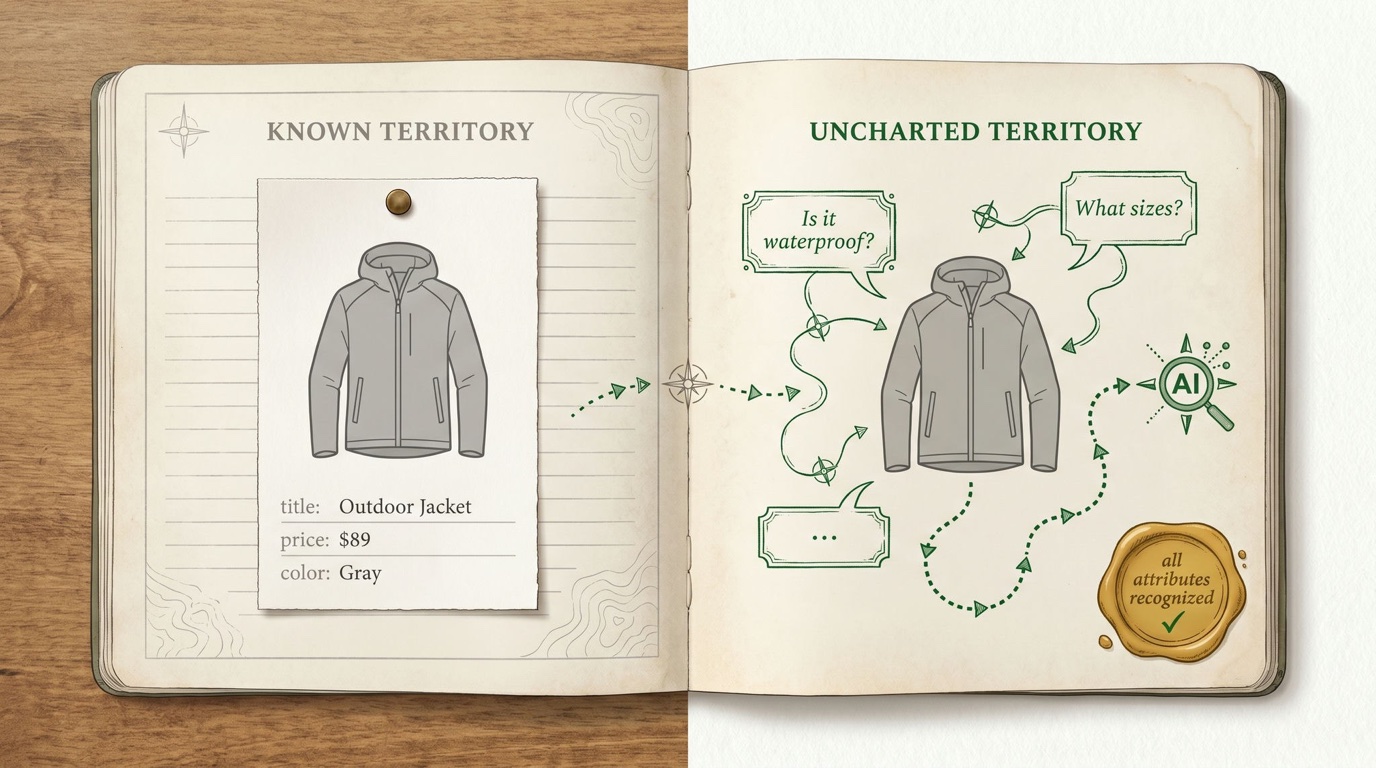
In May 2026, at Google Marketing Live, Google quietly added six new fields to the Merchant Center product spec. No migration deadline, no enforcement, no drama — six optional attributes with a strange collective name: conversational attributes.
Then something unusual happened: the practitioners noticed before the vendors did. Feed managers started posting that they couldn’t actually populate these fields with their existing tools. Not “it’s clunky” — couldn’t. The most established feed platforms in the industry, the ones agencies have run for a decade, had no mechanism for producing what Google was now asking for.
We run a product feed platform for Shopify merchants, which means we had the same problem — and a test environment to attack it with. So we did what you do with a brand-new, undocumented-in-practice capability: we ran the experiment. We generated the new attributes from a real Shopify catalog using a large language model, uploaded them to a real Merchant Center account, collected the processing reports, and wrote down everything — including the parts where we were wrong.
This is the field report. What we know, what we don’t, and what we think the whole industry is about to learn together.
What Google actually shipped
The six fields, per Google’s official documentation:
| Attribute | What it carries | Example |
|---|---|---|
question_and_answer | FAQ-style pairs about the product | "Is this jacket waterproof?":"Yes, rated to 10,000mm." |
document_link | URLs to product PDFs (manuals, spec sheets) | https://example.com/manual.pdf |
related_product | Typed links to other products | required_part:id:AZ7B, accessory:gtin:811571013579 |
item_group_title | The product family name, distinct from the SKU title | Google Pixel 9 (vs. “Google Pixel 9 Pro 512GB Moonstone”) |
variant_option | Structured name:value variant properties | color:moonstone, memory:512GB |
popularity_rank | Product’s popularity as a 0–100 percentile of your inventory | 95.5 |
Why these, and why now? Because the surfaces Google is building — AI Mode in Search, Gemini Shopping, virtual try-on, agentic shopping — don’t work like Shopping ads. Traditional Shopping matched keywords against product titles. AI surfaces answer questions like “best lightweight rain jacket under $150 that packs into its own pocket” — and to answer them, the model behind the surface needs structured facts, not 70-character keyword-stuffed titles. The existing feed spec was never built to carry that kind of information. These six fields are Google admitting it.
Two details from Google’s docs that matter enormously in practice: the attributes are submitted as a supplemental feed (your primary feed is untouched), and Google states they won’t affect existing product approval status. The downside risk of participating early is, by design, near zero.
The false intuition: “it’s just six more columns”
If you’ve managed feeds for a while, your first instinct is the same as ours was: new fields, fine — add them to the column mapping, write a rule or two, done. That’s how every spec update for a decade has worked. sale_price? Map it. shipping_weight? Map it and convert units.
That intuition fails here, and it’s worth being precise about why, because the why determines what kind of tooling can solve it. Walk through it:
Why a Rules Engine Can't Write These Fields
The structural limit every feed tool is hitting right now — demonstrated, not asserted
First, credit where due: the rules paradigm has powered feed optimization for a decade, and for most attributes it's still exactly right. Watch the shape of what it does, though — that shape is about to matter.
This is the structural wall practitioners have been hitting. Joey Bidner — a longtime feed optimization expert — put it publicly: we’re at a paradigm shift in ecommerce account management, and the established tools weren’t built for it. He’s right, and the walkthrough above is the mechanism behind his frustration. A rules engine has three verbs — exclude, set, replace — and all three operate on values that already exist. question_and_answer has no source column. The value has to be authored.
The expedition: what we actually did
Here’s our method, stated plainly so you can judge the results.
The catalog. A Shopify development store with 650 variants across 102 products (50 multi-variant) — apparel, fitness gear, supplements. Full disclosure: it’s a test catalog with synthetic, templated product descriptions. That turned out to be scientifically useful in a way we didn’t expect (more below), but it means our content-quality findings are a floor, not a ceiling. The structural findings — formats, joins, GMC behavior — are fully real.
The generation. We exported each variant’s raw data (title, description, type, vendor, tags, options, prices), derived the two deterministic attributes mechanically, and used Claude to author 3–4 question_and_answer pairs per product for a sample of 18 products under one hard constraint: only state facts present in the input data. No invented specs, no guessed materials, nothing time-sensitive (Google’s editorial guidance explicitly excludes prices and promotional content from these fields).
The submission. A tab-separated file — id plus three attribute columns, 608 rows — uploaded as a supplemental source to a real Merchant Center account linked to the store’s live primary feed.
Here’s one product traced through the entire pipeline, with the real data at every stage:
From Shopify Product to Supplemental Feed Row
One real product from our test catalog, traced end to end. Variant id 47337514827941.
This is the entire input: one product's extracted Shopify data. Title, type, vendor, options, a boilerplate description. Every conversational attribute Google wants has to come from this —or not exist at all.
The grounding problem — the part most coverage skips
Everyone writing about AI-generated feed content focuses on what the model can do. The more important engineering question is what it must refuse to do.
A question_and_answer pair is a product claim that will be served to shoppers by Google’s AI surfaces. If the model answers “Is this jacket waterproof?” without a waterproof rating anywhere in the source data, it hasn’t been helpful — it has manufactured a claim that the merchant is now making to the market. At catalog scale, ungrounded generation isn’t a quality problem; it’s a liability machine.
So the central discipline of our generation harness is grounding: every fact in every answer must trace to a field in the input. Explore what that means in practice — toggle the available source data and watch the answerable question set change:
The Grounding Rule, Made Tangible
Toggle which source data exists. Watch which questions become answerable — and which the model must refuse to invent.
This is the single most important design constraint in LLM-generated feed content. A model that answers "Is this waterproof?" without a waterproof rating in the source data isn't being helpful —it's manufacturing a product claim. The rule we ship with: output quality is capped by input richness. Which is also why metafields — where merchants actually keep specs — are the highest-leverage data source to wire up next.
This experiment produced our single most useful finding, and our synthetic catalog is what surfaced it. Because the test store’s descriptions were templated boilerplate, the model had almost no prose to work with — and the Q&A pairs that were honestly producible came overwhelmingly from structured data: the variant list (“What colors does this come in?”), the vendor, the product type. Conveniently, those are exactly the questions shoppers ask AI surfaces.
The corollary: output quality is capped by input richness, not by model intelligence. A bigger model can’t write a materials answer the data doesn’t contain. For Shopify merchants, the richest untapped input is metafields — where real catalogs keep specs, dimensions, materials, and care instructions. Wiring those into generation will move quality more than any model upgrade.
Field notes: what the upload taught us
The processing report and the road to it produced six discoveries we haven’t seen documented anywhere else. Consider this the section to bookmark.
1. The Supplemental sources tab is hidden behind an add-on. In Merchant Center Next, you will not find supplemental feeds until you enable the “Advanced data source management” add-on (Settings → Add-ons → Discover). Until then, the Data sources page shows only primary sources, and the “Add product source” flow will happily let you upload your supplemental file as a primary feed — which would register your sparse rows as new, attribute-less products. Don’t.
2. Feed label and language are a strict join contract. A supplemental source only attaches to primary sources whose feed label and language match exactly. Multi-feed merchants (multi-country, multi-language) need one supplemental source per combination.
3. TSV, not CSV — Google says so explicitly. The new attribute values are full of commas (color:Gray, size:S; comma-joined Q&A pairs), so Google recommends tab-separated files for exactly this content.
4. The attribute names just… worked. The headline result: Google’s processing report came back “Attribute names: All recognized” for question_and_answer, variant_option, and item_group_title submitted from a plain TSV. No special API, no allowlist, no beta enrollment. The spec is live.
5. 544 of 608 rows matched — and the 64 misses were the best lesson in the experiment. Google reported “Offer does not exist” for 64 rows. We pulled the error report and traced every id: 48 were variants our own feed rules exclude from the primary feed, and 16 were draft (unpublished) products. Zero rows that should have matched failed to match. The production rule this yields: generate supplemental rows from the primary feed’s included set, not from the raw catalog. Your supplemental feed inherits every exclusion your primary feed applies.
6. The generation unit is the product, not the row. “What colors does this come in?” can only be answered by reading all 20 sibling variants together. Feed pipelines think in rows; generation has to think in product groups. This single fact shapes the correct architecture more than anything else on this list.
What it costs (and why the architecture matters more than the model)
The naive mental model of “AI in the feed pipeline” is an agent rewriting your products on every export — and at daily export frequency across thousands of SKUs, that would be slow, expensive, and nondeterministic. The architecture that actually works is duller and better:
Generate once, offline. Cache. Review. Serve deterministically. Q&A pairs are authored per product in a background batch job, stored, and regenerated only when the product’s source data meaningfully changes. The feed export itself — the thing that runs every day — just reads the cache. Zero tokens.
Under that architecture, at mid-2026 batch API pricing, authoring 3–5 grounded Q&A pairs runs roughly $1–5 per 1,000 products depending on model tier — a one-time cost on the order of a coffee for most catalogs, not a recurring tax. The expensive-sounding part of this whole capability is, in practice, the cheapest.
What we know, and what we don’t
An honest expedition publishes both columns.
What we’re now confident of:
- The supplemental-feed path for conversational attributes works today, end to end, with no special access.
- Two of the three highest-value fields are deterministic for Shopify catalogs — no AI required.
question_and_answerrequires synthesis, synthesis requires grounding discipline, and grounded generation is bounded by source-data richness.- The whole thing is economically trivial when generation is offline and cached.
- The failure modes (scoping, feed labels, the add-on gate) are all discoverable and avoidable.
What nobody knows yet — us included:
- The impact question. Does populating these fields measurably increase visibility in AI Mode and Gemini Shopping? Google says
question_and_answeris the highest-impact field, but no one outside Google has published controlled before/after data. This is the experiment that matters next, and it needs real traffic. - The ranking weight. How much do these attributes influence which products AI surfaces select, versus merely enriching how selected products are presented?
popularity_rank’s right signal. Units sold? Revenue? Sell-through velocity? Within what category grouping? Google’s docs define the format, not the methodology.- The review workflow. Should merchants approve every generated pair before submission, or auto-publish with a correction path? At 10,000 products, “review everything” isn’t a workflow — it’s a denial of service against the merchant.
- Whether early matters. The merchants who populated structured data early in past spec shifts (GTINs, product highlights) generally benefited from the head start. Whether that pattern holds for AI surfaces is an open bet — though the cost of placing it is now demonstrably small.
Where this goes
Our working thesis, sharpened considerably by this experiment: the feed industry’s decade-old paradigm — map columns, write rules — isn’t being replaced. It’s being layered. The deterministic pipeline remains the substrate: reproducible, auditable, cheap. Above it sits a generation layer that authors the content rules can’t, offline and grounded. And eventually, above that, something more agentic — systems that read a merchant’s catalog and their channel’s validation feedback and propose the configuration a feed consultant would. That last layer is where we think this ends up; the supplemental feed is where it starts, because it’s the one place you can add value today without touching anything that already works.
If you take one thing from this report: the door Google opened is real, it’s open right now, and walking through it costs almost nothing. The fields parse. The economics work. The unknowns are about impact magnitude, not feasibility.
An invitation
This was one expedition, on one catalog, by one team. The conversation Google started is bigger than any single vendor’s roadmap, and the practitioners pushing on this — agencies, in-house feed managers, the people in Joey Bidner’s comment sections — are generating the real field data.
So: if you’re experimenting with conversational attributes — or trying to and hitting walls — we want to compare notes. If you’re a Shopify merchant with a rich catalog who wants to be an early case study (with real before/after AI-surface data we can publish), even better. The next report in this series should have impact numbers in it, and that takes real catalogs and real traffic.
Ready to simplify your product feeds?
Simple Product Feeds connects your Shopify store to Google Shopping, Meta, and more — in minutes.
Install Simple Product FeedsFrequently Asked Questions
- What are Google's conversational attributes?
- Conversational attributes are six new optional fields announced at Google Marketing Live 2026 for Google Merchant Center: question_and_answer, document_link, related_product, item_group_title, variant_option, and popularity_rank. They exist to feed AI-driven shopping surfaces — AI Mode in Search, Gemini Shopping, virtual try-on, and agentic shopping experiences — which parse structured attributes to answer natural-language queries rather than matching keywords against titles.
- Do conversational attributes affect my product approval status?
- No. Google has stated that adding conversational attributes won't affect existing product approval status. They're submitted via a supplemental feed, which structurally can only add or update attributes on existing products — it cannot add, remove, or disapprove products. In our test upload, Google processed all three attributes without touching any product's status.
- Can rules-based feed tools generate conversational attributes?
- Partially. Two of the six (item_group_title and variant_option) are deterministic mappings from Shopify's data model that any feed tool could implement, and popularity_rank is a calculation over order data. But question_and_answer requires synthesizing new text from data spread across multiple fields and sibling variants — an operation rules engines structurally cannot perform, because every rule primitive transforms a value that already exists. This is why practitioners are reporting that traditional feed tools are stuck on these fields.
- How are conversational attributes submitted to Google Merchant Center?
- Via a supplemental data source: a sparse file containing the product id plus only the new attribute columns, linked to your primary feed. In Merchant Center Next you must first enable the 'Advanced data source management' add-on (Settings → Add-ons) before the Supplemental sources tab appears. The supplemental source's feed label and language must exactly match the primary feed's. Google recommends TSV format because the new attribute values contain commas.
- What does LLM generation of question_and_answer cost?
- Roughly $1–5 per 1,000 products at mid-2026 API pricing, depending on the model tier, using batch processing. Critically, it's mostly a one-time cost: pairs are generated once per product, cached, and regenerated only when the product's source data changes. The daily feed export serves cached values and costs zero AI tokens.
- Which conversational attribute should merchants prioritize?
- Google flags question_and_answer as the highest-impact field for AI surface visibility, and it's also the hardest to produce — making it the differentiator. item_group_title and variant_option are near-free for Shopify catalogs and worth shipping immediately as the baseline. popularity_rank requires order data access and is a strong second wave.
Related Articles
DataFeedWatch Alternative for Shopify: An Honest Comparison
Looking for a DataFeedWatch alternative? See why Shopify merchants switch to Simple Product Feeds — Shopify-native, transparent pricing from $9.99/mo, free plan.

Your Shopify Product Feed Is a Testing Platform — Here's How to Use It
Most merchants treat their feed as a sync task. Here's how google shopping feed optimization with feed rules generates real marketing signal — and what to do with it.
How to Optimize Your Shopify Product Feed (Complete Guide)
Optimize your Shopify product feed for Google Shopping with this step-by-step guide. Fix titles, categories, GTINs, and feed rules to get more impressions and clicks.